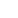在现代化的机场航站楼内,公共显示屏已然成为了信息传递和形象展示的关键设施。它们分布于出发厅、到达厅、贵宾厅等各个角落,为乘客提供即时的航班动态、广告信息和机场服务。然而,随着显示屏数量的增加和内容的多样化,如何确保播放内容的安全性和合规性,成为了机场管理面临的一大挑战。

在繁忙的机场,公共显示屏已成为不可或缺的信息传递工具。它们不仅为旅客提供航班动态、登机口信息等实用数据,还承载着展示机场形象、提升旅客体验的重要使命。然而,随着显示屏的广泛应用,其内容安全问题也日益凸显,如何确保显示屏内容的安全与合规性,成为了一个亟待解决的问题。

在机场航站楼的出发厅、到达厅以及各个贵宾厅,我们都可以看到各式各样的公共显示屏。它们不仅是信息传递的重要媒介,也是机场形象展示的窗口。然而,这些显示屏也面临着内容安全与合规性的挑战。如何确保播放内容的准确性和安全性,成为了一个亟待解决的问题。

在高速公路上,情报板是一个神秘而又充满魔力的存在。它们如同会说话的路标,为我们提供着实时交通信息和路况预警。但你知道吗?这些情报板也有自己的“小秘密”。

在信息时代的高速公路上,情报板作为重要的信息传递媒介,其内容的安全性和准确性对于公众的出行和生活具有重要意义。然而,近年来情报板内容被篡改、发布不实信息等安全事故频发,引发了人们对情报板内容安全性的关注和思考。

在当今快节奏的交通环境中,高速公路情报板作为信息传递的重要媒介,发挥着不可或缺的作用。它们不仅为驾驶员提供实时的交通信息和预警,还承载着传递社会正能量、保障公众安全顺畅出行的使命。然而,随着信息技术的迅猛发展,情报板内容的安全性也面临着前所未有的挑战。